




















Việc các loại Chat GPT có những nội dung trả lời khác biệt với đường lối tuyên truyền của nhà nước, đang khiến nhiều người vui cười gần đây. Nhưng đó là một niềm vui ngắn hạn và tuyệt vọng.
Chat GPT dựa vào những nguồn dữ liệu truyền thông sẵn có để tạo ra những trả lời và nhận định, nhưng giá trị của các nguồn dữ liệu truyền thông trong tương lai cũng sẽ bị thao túng và thay đổi rất nhiều, tương tự như câu chuyện wikipedia luôn luôn bị giành giật mô tả những vấn đề lịch sử của Miền Nam trước 1975.
Vì các hệ thống Open AI, Bard… nói chung là AI Powers chưa chính thức đưa vào Việt Nam, do đó nó chưa bắt đầu phải bị buộc sử dụng các nguồn dữ liệu duy nhất mà Việt Nam đang quy định theo luật, giống như kiểu Facebook hay Google vẫn xóa bài hay khóa trang của những người trình bày mà không cùng quan điểm nhà nước, và xem nó như cách thống nhất tư duy và dữ liệu.
Các nhà nước như Trung Quốc, Việt Nam… vốn vẫn dành ngân sách lớn cho các lực lượng hoạt động trên mạng luôn chỉnh sửa lại lịch sử, và duy trì các câu chuyện đã “lỡ” hình thành như Lê Văn Tám, thì tương lai của lịch sử VN đang bị trao vào tay các thể chế có thói quen thích thể hiện lịch sử qua lăng kính chính trị riêng của mình.
Chuyện các thời đại triều Nguyễn lại tiếp tục bị chà đạp và phỉ báng vô tội vạ, Alexandre de Rhodes sẽ ngày càng được chứng minh là việc tạo ra tiếng Việt chỉ làm công cụ cho Pháp xâm lược, Phan Thanh Giản, Trương Vĩnh Ký, Nguyễn Văn Vĩnh, Phạm Quỳnh… mãi mãi bị treo trước giá tội đồ đối với thuyết khung định lịch sử từ nhà cầm quyền.
Đối phó với AI Powers, có tin Trung Quốc đang hình thành dạng nhóm viết dữ liệu và sử dụng như đó là nguồn chính thức quốc gia theo ý của Đảng Cộng Sản, trong đó Tây Tạng được mô tả như là một vùng đất khát khao được giải phóng và mang ơn Bắc Kinh.
Giữa năm ngoái, tờ Techcrunch đã tiết lộ chuyện trong hệ thống cầm quyền của Trung Quốc cho lưu hành một tập tài liệu, nói về định hình sự phát triển công nghệ của Trung Quốc trong vài năm phải được định hướng rõ là “chủ quyền kỹ thuật số” – ám chỉ khả năng của một quốc gia trong việc phải biết kiểm soát “vận mệnh kỹ thuật số” của chính mình, bao gồm quyền tự chủ đối với phần mềm và phần cứng quan trọng trong chuỗi cung ứng AI. Các đợt cấm xuất khẩu của Hoa Kỳ đối với Trung Quốc là cơ hội thúc đẩy Bắc Kinh tiếp tục kêu gọi độc lập về công nghệ trong các lĩnh vực từ chất bán dẫn đến nghiên cứu cơ bản về AI.
Khi ChatGPT của OpenAI xuất hiện, cho thấy tiềm năng phá vỡ các rào cản bị kiểm duyệt hoặc bưng bít từ giáo dục, tin tức đến dịch vụ… Trung Quốc đã ra chỉ thị là muốn phát triển các ChatGPT cây nhà lá vườn của mình, không chỉ để đảm bảo quyền kiểm soát cách dữ liệu truyền qua các công cụ đó, mà còn để tạo ra các sản phẩm Ai đặc thù văn hóa và chính trị của chủ nghĩa cộng sản.
Nhờ chuẩn bị trước, dự kiến ra mắt vào tháng 3 năm này, robot đàm thoại của Baidu trước tiên sẽ được tích hợp vào công cụ tìm kiếm của hãng, theo tin từ The Wall Street Journal. Điều đó cho thấy chatbot sẽ chủ yếu tạo ra kết quả bằng tiếng Trung Quốc. Tuy nhiên, mô hình học sâu được đào tạo trên cả nguồn dữ liệu tiếng Trung và tiếng Anh, bao gồm cả thông tin thu thập được bên ngoài Bức tường lửa vĩ đại, cơ sở hạ tầng kiểm duyệt internet phức tạp của đất nước.
Giống như tất cả mọi kênh thông tin trói buộc con người ở Trung Quốc, chatbot của Baidu chắc chắn sẽ phải tuân theo các quy định và quy tắc kiểm duyệt của Bắc Kinh. Hiện điều này đã xuất hiện cụ thể, như ứng dụng chuyển văn bản thành hình ảnh của công ty ERNIE-VilG, đã từ chối câu từ bị coi là “nhạy cảm” về chính trị. Nhưng AI đàm thoại xử lý các yêu cầu phức tạp hơn nhiều so với trình tạo hình ảnh — nên người ta vẫn theo dõi xem đứa con cưng của Bắc Kinh là Baidu sẽ vượt qua ranh giới giữa sự kiểm duyệt hạn chế, để được sự tự do và sáng tạo cho bot của mình như thế nào?
Ở Việt Nam, người học trò chăm chỉ của Bắc Kinh về kiểm duyệt, mạng Báo Điện tử Chính phủ Việt Nam ngày 6 Tháng Hai 2023 có dẫn trả lời của Viện trưởng Viện Công nghệ- Thông tin (Viện CN-TT) Việt Nam, PGS-TS Nguyễn Trường Thắng trong một cuộc phỏng vấn đã mơ hồ nhắc về các khung kiểm duyệt thông tin có thể bị vỡ, nếu không dùng luật khống chế. “Việt Nam cần sớm nghiên cứu và ban hành các khuôn khổ pháp lý liên quan, bảo đảm việc ứng dụng trí tuệ nhân tạo (AI) vào các công việc một cách rõ ràng, chỉ rõ nguồn gốc các phần được tạo ra từ những công cụ hỗ trợ thông minh như thế”. Ông Thắng nói. Dĩ nhiên là vì các công cụ AI Powers đó không quan tâm đến việc bị bỏ tù vì điều 117 hay 331,
Chắc chắn, một khi AI quốc tế được phát hành chính thức để kiếm tiền ở Trung Quốc hay Việt Nam, thì cũng theo luật của quốc gia, AI bị buộc phải truy xuất duy nhất từ nguồn dữ liệu chỉ định.
Công cụ tiên tiến được làm ra đây phục vụ loài người. Nhưng đôi khi những công cụ đó bị kiểm soát không đúng với tinh thần ra đời của nó, cũng sẽ là một đại nạn với một nhóm người hay một dân tộc./.

")



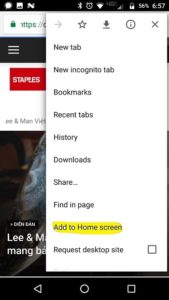
 2/ Mở menu của Safari, nơi cuối màn hình, ô có mũi tên, kéo về phía trái cho đến khi thấy ô “Add to home screen”.
2/ Mở menu của Safari, nơi cuối màn hình, ô có mũi tên, kéo về phía trái cho đến khi thấy ô “Add to home screen”.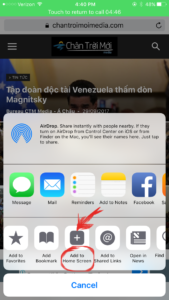 Bấm ô đó là xong. Bạn đã có icon ngay trên home screen như hình bên dưới.
Bấm ô đó là xong. Bạn đã có icon ngay trên home screen như hình bên dưới.
{kind=link}